Artificial general intelligence (AGI) is back in the news thanks to the recent introduction of Gato from DeepMind. As much as anything, AGI invokes images of the Skynet (of Terminator lore) that was originally designed as threat analysis software for the military, but it quickly came to see humanity as the enemy. While fictional, this should give us pause, especially as militaries around the world are pursuing AI-based weapons.
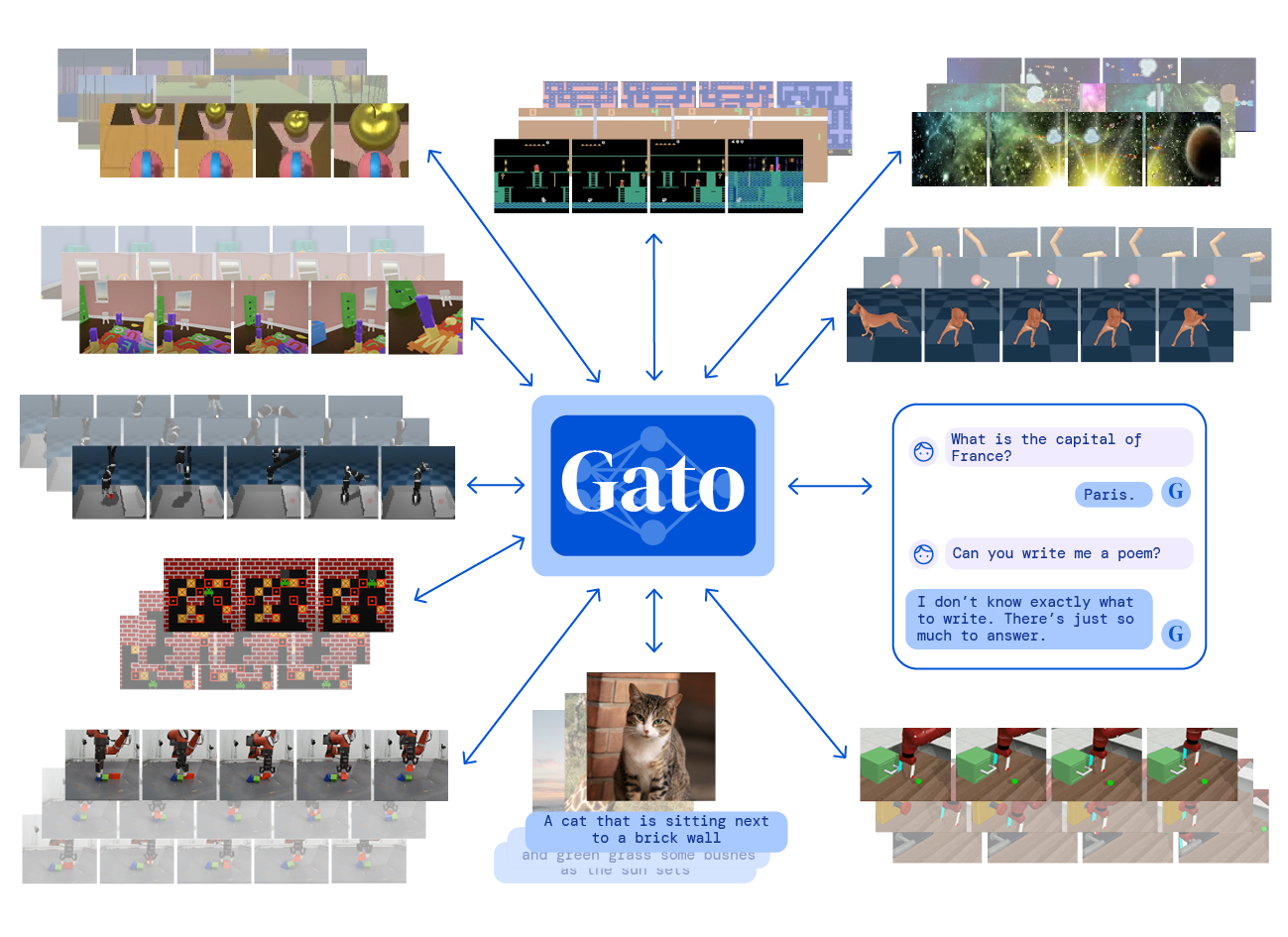
However, Gato does not appear to raise any of these concerns. The deep learning transformer model is described as a “generalist agent” and purports to perform 604 distinct and mostly mundane tasks with varying modalities, observations and action specifications. It has been referred to as the Swiss Army Knife of AI models. It is clearly much more general than other AI systems developed thus far and in that regard appears to be a step towards AGI.
Multimodal neural networks
Multimodal systems are not new — as evidenced by GPT-3 and others. What is arguably new is the intent. By design, GPT-3 was intended to be a large language model for text generation. That it could also produce images from captions, generate programming code and other functions were add-on benefits that emerged after the fact and often to the surprise of AI experts.
By comparison, Gato is intentionally designed to address many discrete functions. DeepMind explains that, “The same network with the same weights can play Atari, caption images, chat, stack blocks with a real robot arm and much more, deciding based on its context whether to output text, joint torques, button presses or other tokens.”
Though DeepMind claims Gato outperforms humans for many of these tasks, the first iteration yields less than impressive outcomes on several activities. Observers have noted that it does not perform many of the 604 tasks particularly well, with one observer who summarized it as: “One AI program that does a so-so job at a lot of things.”
But this dismissal misses the point. Up to now, there has only been “narrow AI” or “weak AI,” defined as being adept at only a single dedicated purpose, with ‘single purpose’ meaning a couple of things:
- An algorithm designed to do one thing (say, develop beer recipes) cannot be used for anything else (play a video game, for example).
- Anything one algorithm “learns” cannot be effectively transferred to another algorithm designed to fulfill a different specific purpose.
For example, AlphaGo, the neural network also from DeepMind that outperformed the human world champion at the game of Go, cannot play other games despite those games being much simpler and cannot fulfill any other need.
Strong AI
The other end of the AI spectrum is deemed “strong AI” or alternatively, AGI. This would be a single AI system — or possibly a group of linked systems — that could be applied to any task or problem. Unlike narrow AI algorithms, knowledge gained by general AI can be shared and retained among system components.
In a general AI model, the algorithm that can beat the world’s best at Go would be able to learn chess or any other game, as well as take on additional tasks. AGI is conceived as a generally intelligent system that can act and think much like humans. Murray Shanahan, a professor of cognitive robotics at Imperial College in London, said on the Exponential View podcast that AGI is “in some sense as smart as humans and capable of the same level of generalization as human beings are capable of and possesses common sense that humans have.”
Albeit, unlike humans, it performs at the speed of the fastest computer systems.
A matter of scale
Nando de Freitas, a researcher at DeepMind, believes Gato is effectively an AGI demonstration, only lacking in the sophistication and scale that can be achieved through further model refinement and additional computing power. The size of the Gato model is relatively small at 1.18 billion parameters, essentially a proof of concept, leaving a lot of upside performance with additional scaling.
Scaling the AI models requires more data and more computing power for algorithm training. We are awash in data. Last year, industry analyst firm IDC said, “The amount of digital data created over the next five years will be greater than twice the amount of data created since the advent of digital storage.” Furthermore, computing power has increased exponentially for decades. Though there is evidence, this pace is slowing due to constraints on the physical size of semiconductors.
Nevertheless, the Wall Street Journal notes that chipmakers have pushed the technological envelope, finding new ways to cram in more computing power. Mostly this is done through heterogeneous design, building chips from a wide variety of specialist modules. This approach is proving effective, at least in the near term, and this will continue to drive model scale.
Geoffrey Hinton, a University of Toronto professor who is a pioneer of deep learning, spoke to scale stating that: “There are one trillion synapses in a cubic centimeter of the brain. If there is such a thing as general AI, [the system] would probably require one trillion synapses.”
AI models with one trillion plus parameters – the neural network equivalent of synapses – are emerging, with Google having developed a 1.6-trillion-parameter model. Yet, this is not an example of AGI. The consensus of several surveys of AI experts suggests AGI is still decades into the future. Either Hinton’s assessment is only part of the issue for AGI or the expert opinions are conservative.
Perhaps the merits of scale are best displayed with the advance from GPT-2 to GPT-3 where the difference was mostly more data, more parameters — 1.5 billion with GPT-2 to 175 billion with GPT-3 — and more computing power — e.g., more and faster processors, with some designed specifically for AI functionality. When GPT-3 appeared, Arram Sabeti, a San Francisco–based developer and artist, tweeted “Playing with GPT-3 feels like seeing the future. I’ve gotten it to write songs, stories, press releases, guitar tabs, interviews, essays, technical manuals. It’s shockingly good.”
However, AI deep learning skeptic Gary Marcus believes that “There are serious holes in the scaling argument.” He claims that scaling measures others have looked at, such as predicting the next word in a sentence, is “not tantamount to the kind of deep comprehension true AI [AGI] would require.”
Yann LeCun, chief AI scientist at Facebook’s owner Meta and a past winner of the Turing Award for AI, said in a recent blog post after the publication of Gato that as of now there is no such thing as AGI. Moreover, he doesn’t believe that scaling-up models will reach this level, that it will require additional new concepts. Though he does concede that some of these concepts, such as generalized self-supervised learning, “are possibly around the corner.”
MIT Assistant Professor Jacob Andreas argues that Gato can do many things at the same time, but that is not the same as being able to meaningfully adapt to new tasks that are different from what it was trained to do.
While Gato may not be an example of AGI, there is no denying it provides a significant step beyond narrow AI. It provides further proof that we are entering a twilight zone, an ill-defined area between narrow and general AI. AGI as discussed by Shanahan and others could still be decades into the future, though Gato may have accelerated the timeline.
Gary Grossman is the senior VP of technology practice at Edelman and global lead of the Edelman AI Center of Excellence.
DataDecisionMakers
Welcome to the VentureBeat community!
DataDecisionMakers is where experts, including the technical people doing data work, can share data-related insights and innovation.
If you want to read about cutting-edge ideas and up-to-date information, best practices, and the future of data and data tech, join us at DataDecisionMakers.
You might even consider contributing an article of your own!
Read More From DataDecisionMakers
Source: Read Full Article